
ランキングサイトの掲載情報を全て自動で取得する方法
今回の講義はめちゃくちゃ重要でした。
とにかく実践的で、どのように自動で取得すればいいか、
コードを書いていく上で必要な基礎知識などとてもわかりやすく
教えてくれます。
今回も今西先生が講義の為に作成されたwebページを使用します。
https://scraping-for-beginner.herokuapp.com/ranking/
ランキング形式でいろんな観光地情報が入ったページです。
この講義の流れ
講義の流れとしては今まで学んできた事の応用みたいな感じで
とりあえ1番の観光地情報から
・場所の特定
・情報の取得
の流れで各項目の情報を取得していき、
それをデータとしてまとめていきます。
その1番の観光地情報を取得したコードを元に
10番までの観光地情報をfor文の繰り返し処理で全て取得していきます。
コードの実装
まずは前回同様
requests と BeautifulSoup をインポート。
今回スクレイピングする今西先生のサイトURLを変数に代入。
get()メソッドで取得したページ情報をres = とします。
res.text の情報を BeautifulSoup html parser で
読みやすい情報に変えて、そのインスタンス名をsoupとします。
import requests
from bs4 import BeautifulSoup
url = 'https://scraping-for-beginner.herokuapp.com/ranking/'
res = requests.get(url)
soup = BeautifulSoup(res.text , 'html.parser')1つの観光地情報の取得
まずは一つの観光地情報を取得します。
ここで活躍するのが前回の講義でも出てきた
chromeの検証ツールです。
webページ上で右クリックするとでてきます。
実際のサイトでいろいろクリックしてみると
1つ1つの観光地を大枠でくくっている塊を見つける事ができます。
この'u_areaListRankingBox row'の中に1つの観光地情報が
入っているのを見つけることができます。
開けてみるとこんな感じです。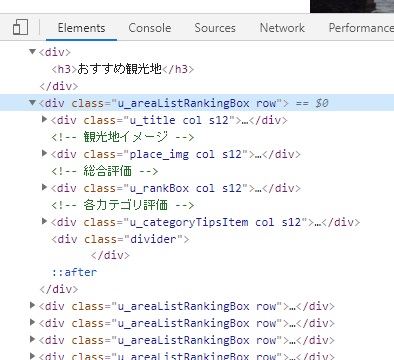
なのでここから情報を取得していきます。
観光地名の取得
#観光地名取得
#検証ツールで見た通りu_areaListRankingBoxは10個あるのでリスト形式で取得できます。
#なのでspotsと複数系の変数をつけます。
spots = soup.find_all('div',attrs={'class':'u_areaListRankingBox'})
#まず一つ目の観光地情報のみを取得します
spot = spots[0]
#spotから観光地名を取得
spot_name = spot.find('div',attrs={'class':'u_title'})
spot_name
<div class="u_title col s12">
<p><h2><span class="badge">1</span>観光地 1</h2></p>
</div>
spot_name.text
'\n1観光地 1\n'
#観光地の前の1を無くす
#消したい情報の部分を抽出
#抽出した情報をextract()で削除できる
spot_name.find('span',attrs={'class':'badge'}).extract()
<span class="badge">1</span>
#replaceで\n を''に置き換える
spot_name = spot_name.text.replace('\n','')
spot_name
'観光地 1'評点の取得
#総合評価の入っているclassを探す
eval_num = spot.find('div',attrs={'class':'u_rankBox'}).text
eval_num
'\n4.7\n'
#\nをreplaceで削除
#このままだと文字列なのでfloatに変換
eval_num = float(eval_num.replace('\n',''))
eval_num
4.7各カテゴリーの評価を取得
#各カテゴリー評価の入った'u_categoryTipsItem'から情報を取得
categoryItems = soup.find('div',attrs={'class':'u_categoryTipsItem'})
categoryItems
#同じ構造の物がならんでいます。
categoryItems = categoryItems.find_all('dl')
#リスト形式で情報が入っているので
#まず1番目の楽しさから情報を取得
categoryItem = categoryItems[0]
categoryItem
<dl>
<dt>楽しさ</dt>
<dd class="is_rank"><span class="evaluateNumber">4.6</span></dd>
<dd class="comment">THE非日常</dd>
</dl>
#楽しさ取得
category = categoryItem.dt.text
category
'楽しさ'
#楽しさの評価を取得
rank = float(categoryItem.span.text)
rank
4.6
#for文をつかい辞書型で情報を取得
#まず必要な項目を集める
details = {}
categoryItem = categoryItems[0]
category = categoryItem.dt.text
rank = float(categoryItem.span.text)
details[category ]=rank
#for文に変換
details = {}
for categoryItem in categoryItems:
category = categoryItem.dt.text
rank = float(categoryItem.span.text)
details[category ]=rank
details
{'楽しさ': 4.6, '人混みの多さ': 4.5, '景色': 4.9, 'アクセス': 4.2}観光地名・評点・各カテゴリーの評価 をまとめて取得
#すべての情報をまとめる
soup = BeautifulSoup(res.text , 'html.parser')
spots = soup.find_all('div',attrs={'class':'u_areaListRankingBox'})
spot = spots[0]
spot_name = spot.find('div',attrs={'class':'u_title'})
spot_name.find('span',attrs={'class':'badge'}).extract()
spot_name = spot_name.text.replace('\n','')
eval_num = spot.find('div',attrs={'class':'u_rankBox'}).text
eval_num = float(eval_num.replace('\n',''))
categoryItems = soup.find('div',attrs={'class':'u_categoryTipsItem'})
categoryItems = categoryItems.find_all('dl')
details = {}
for categoryItem in categoryItems:
category = categoryItem.dt.text
rank = float(categoryItem.span.text)
details[category ]=rank
datum = details
datum['観光地名'] = spot_name
datum['評点']=eval_num
#for 文に変換
#datumに入った1件ごとの観光地情報を入れていくdataを定義
#appendでdataに追加していく
data=[]
soup = BeautifulSoup(res.text , 'html.parser')
spots = soup.find_all('div',attrs={'class':'u_areaListRankingBox'})
for spot in spots:
spot_name = spot.find('div',attrs={'class':'u_title'})
spot_name.find('span',attrs={'class':'badge'}).extract()
spot_name = spot_name.text.replace('\n','')
eval_num = spot.find('div',attrs={'class':'u_rankBox'}).text
eval_num = float(eval_num.replace('\n',''))
categoryItems = soup.find('div',attrs={'class':'u_categoryTipsItem'})
categoryItems = categoryItems.find_all('dl')
details = {}
for categoryItem in categoryItems:
category = categoryItem.dt.text
rank = float(categoryItem.span.text)
details[category ]=rank
datum = details
datum['観光地名'] = spot_name
datum['評点']=eval_num
data.append(datum)
data
[{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 1',
'評点': 4.7},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 2',
'評点': 4.7},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 3',
'評点': 4.6},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 4',
'評点': 4.5},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 5',
'評点': 4.5},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 6',
'評点': 4.4},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 7',
'評点': 4.3},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 8',
'評点': 4.3},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 9',
'評点': 4.2},
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': '観光地 10',
'評点': 4.1}]CSVで出力
import pandas as pd
df = pd.DataFrame(data)
df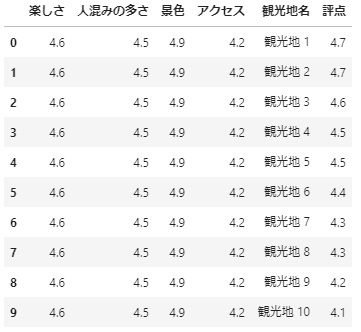
無事データフレームに格納することができました。
後は観光地名と評点を前に持ってきて見栄えをよくします。
df.columns
Index(['楽しさ', '人混みの多さ', '景色', 'アクセス', '観光地名', '評点'], dtype='object')
df = df[['観光地名', '評点','楽しさ', '人混みの多さ', '景色', 'アクセス']]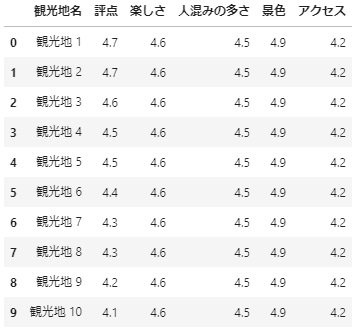
最後はcsvに書き出して終わりです。
indexは書き出さないようにします。
df.to_csv('test.csv', index=False)

コメント