
WEBページ上の画像を一括取得する方法
こちらの講義は
・画像一覧サイトから画像を一括で取得した
・特定のページから画像のみを抽出した
というケースを想定した内容みたいです。
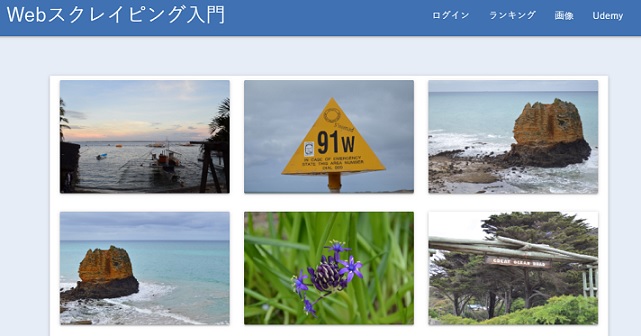
今回の講義でも今西先生が講義ように製作された
webページをつかって学んでいきます。
https://scraping-for-beginner.herokuapp.com/image
まずはいつもの通り、
必要なモジュールをimport。
変数urlに講義用webページのアドレスを入れて
get()メソッドでhtmlデータを取得してそれをresとします。
res.textをBeautifulSoup でhtml.parserして形を整えた
ものをsoupと名付けます。
import requests
from bs4 import BeautifulSoup
url = 'https://scraping-for-beginner.herokuapp.com/image'
res = requests.get(url)
soup = BeautifulSoup(res.text , 'html.parser')まずは一つの画像を取得
初めから一括で画像を取得するのではなく、
今回もまずは一つの画像を取得していきます。
find_allでなはくfindで1番初めの画像を取得します。
img_tag = soup.find('img')
img_tag
<img class="materialbox responsive-img card" src="/static/assets/img/img1.JPG"/>画像のアドレスをみてみると
/static/assets/img/img1.JPG
となっています。
相対パスとなっていますので、実際はhttpからはじまる
アドレスが必要です。
なのでまずは/static/assets/img/img1.JPG
を取得して、http~ の部分をつなげます。
img_tag['src']
'/static/assets/img/img1.JPG'
root_url = 'https://scraping-for-beginner.herokuapp.com/'
img_url = root_url + img_tag['src']
img_url
'https://scraping-for-beginner.herokuapp.com//static/assets/img/img1.JPG'画像の保存
まずは画像の保存に必要なモジュールをインストールします。
そしてimport。
!pip install pillow
from PIL import Image
import ioここからのコードは実際に画像を保存する部分なのですが、
こういうものだと覚えてしまった方がいいみたいです。
img = Image.open(io.BytesIO(requests.get(img_url).content))
img
すると実際に画像を取得することができます。
この画像を保存します。
img.save('img/sample.jpg')複数の画像を取得・保存
1つの画像の取得に成功しましたので、
今度は一括で画像を取得します。
まずは1枚の画像を保存するコードをまとめます。
#1枚の画像を取得するために必要なコード
soup = BeautifulSoup(res.text , 'html.parser')
img_tag = soup.find('img')
root_url = 'https://scraping-for-beginner.herokuapp.com/'
img_url = root_url + img_tag['src']
img = Image.open(io.BytesIO(requests.get(img_url).content))
img.save('img/sample.jpg')
このまとめたコードをfor文にすればいいのかとおもいきや、
このままfor 文でまわしても、画像名が同じで出力されるので
全て上書きされてしまいます。
そこで要素番号とindexを同時に取得する
enumerate関数を使います。
試しにprint文で出力してみます。
soup = BeautifulSoup(res.text , 'html.parser')
img_tags = soup.find_all('img')
for i,img_tag in enumerate(img_tags):
print(i , img_tag)
0 <img class="materialbox responsive-img card" src="/static/assets/img/img1.JPG"/>
1 <img class="materialbox responsive-img card" src="/static/assets/img/img2.JPG"/>
2 <img class="materialbox responsive-img card" src="/static/assets/img/img3.JPG"/>
3 <img class="materialbox responsive-img card" src="/static/assets/img/img4.JPG"/>
4 <img class="materialbox responsive-img card" src="/static/assets/img/img5.JPG"/>
5 <img class="materialbox responsive-img card" src="/static/assets/img/img6.JPG"/>
6 <img class="materialbox responsive-img card" src="/static/assets/img/img7.JPG"/>
7 <img class="materialbox responsive-img card" src="/static/assets/img/img8.JPG"/>
8 <img class="materialbox responsive-img card" src="/static/assets/img/img9.JPG"/>
9 <img class="materialbox responsive-img card" src="/static/assets/img/img10.JPG"/>
10 <img class="materialbox responsive-img card" src="/static/assets/img/img11.JPG"/>
11 <img class="materialbox responsive-img card" src="/static/assets/img/img12.JPG"/>
12 <img class="materialbox responsive-img card" src="/static/assets/img/img13.JPG"/>
13 <img class="materialbox responsive-img card" src="/static/assets/img/img14.JPG"/>
14 <img class="materialbox responsive-img card" src="/static/assets/img/img15.JPG"/>
15 <img class="materialbox responsive-img card" src="/static/assets/img/img16.JPG"/>
16 <img class="materialbox responsive-img card" src="/static/assets/img/img17.JPG"/>
17 <img class="materialbox responsive-img card" src="/static/assets/img/img18.JPG"/>
18 <img class="materialbox responsive-img card" src="/static/assets/img/img19.JPG"/>
19 <img class="materialbox responsive-img card" src="/static/assets/img/img20.JPG"/>
20 <img class="materialbox responsive-img card" src="/static/assets/img/img21.JPG"/>
21 <img class="materialbox responsive-img card" src="/static/assets/img/img22.JPG"/>
22 <img class="materialbox responsive-img card" src="/static/assets/img/img23.JPG"/>
23 <img class="materialbox responsive-img card" src="/static/assets/img/img24.JPG"/>
index番号と要素を取得できたので
index番号を f ストリング関数をつかって画像名に入れて
for文を完成させます。
soup = BeautifulSoup(res.text , 'html.parser')
img_tags = soup.find_all('img')
for i,img_tag in enumerate(img_tags):
root_url = 'https://scraping-for-beginner.herokuapp.com/'
img_url = root_url + img_tag['src']
img = Image.open(io.BytesIO(requests.get(img_url).content))
#fストリング関数
img.save(f'img/{i}.jpg')


コメント