
スクレイピングする題材
今回のスクレイピングでは
selenium
chromdriver
を使って検索結果をデータ化しようと思います。
題材は家電量販店のEDIONさんの公式通販サイトです。

ここからの内容についてはpythonのプログラムを
jupyter notebook
で記述していきます。
インストールなどまだな方は予めインストールが必要です。
"jupyter notebook" "インストール"などで
ググっていただくといいかと思います。
スクレイピング可能かどうか調べる
まずは対象のサイトがスクレイピング可能かどうか調べます。
EDIONさんの公式通販の利用規約へ
エディオンさんの公式サイト利用規約はこちら

Windowsの方なら Ctrl + F 、
Macの方なら command + F
でページ内の文言を検索することができますので、
[ロボット、自動、スクレイピング、クローリング]
などの単語で検索結果が出てこなければ概ね大丈夫です。
とはいえ、相手方サーバーに負荷のかかりにくいプログラムを
作る必要はあります。
web driver + Selenium でbrowser操作
seleniumというプラウザーに命令をするライブラリと
chromeを操作するために必要なweb driverを使って情報を取得していきます。
通常、正確にブラウザーを操作する為には
chromeのバージョンとweb driverのバージョンを合わせる必要があります。
webdriver_manager
ただ、ブラウザであるchromeはアップデートなどでバージョンが
変わってしまうことが多々あります。
そこでwebdriver_managerをインポートすることによって
起動の度にchromeのバージョンに合わせてたドライバーを
その都度インストールして使用する事ができます。
まずはselenium, webdriver_managerのインストールです。
seleniumに関してはすでにインストールしている場合もありますので
アップデートする形でインストールします。
#-Uをつける事でなにかアップデートがあれば更新してくれる。
!pip3 install -U selenium
#都度、最適なweb driverをインストールしてくれます。
!pip3 install webdriver_managerライブラリのインストール
スクレイピングに必要なライブラリをimport します。
#seleniumのインポート
from selenium import webdriver
#web driverのインポート
from webdriver_manager.chrome import ChromeDriverManagerURLへの検索文字の挿入
以前スクレイピングをしたケーズデンキの場合もそうでしたが、
通常のスクレイピングの場合、
定まったURLを変数に入れてスクレイピングするのですが、
今回は検索文字を入力して結果をデータ化します。
通常検索窓に検索文字をいれて検索するとURLは下記のようになります。
今回は 扇風機 と入力してみました。
https://www.edion.com/item_list.html?keyword=%E6%89%87%E9%A2%A8%E6%A9%9F
おそらく keyword= のあとが検索文字だと思われます。
ここらか、このような結果にするにはどうしたものかと
いろいろ調べました(笑)
で、結局どういう原理か細かい部分までは理解していませんが、
下記コードで文字の変換が可能であることがわかりました。
#入力した検索文字を変改してURLを作成
key_word='扇風機'
post_data = {'KEY1':key_word}
urlencode_post_data = urllib.parse.urlencode(post_data, encoding='')これで変換できることはわかったのですが、
encoding='' の部分に今回のEDIONさんのサイトにあう文字コード
を入れなければいけません。
プログラムに詳しい人だとスマートに見つけることができるんだと思うのですが
私の場合はひたすらいろんな文字コードを入れてみました(笑)
その結果、今回は encoding='utf-8' でいけました。
で、今回の変換プログラムですが、
KEY1= の形で出力されますので、検索urlに入れるときは
KEY1= を取り除く必要があります。
#変換された検索文字をフォーマット文の型でいれます{}
url = 'https://www.edion.com/item_list.html?keyword={}'
#フォーマト文の形で検索文字をいれて変数target_urlにいれます。
target_url = url.format(urlencode_post_data)
#不要なKEY1=を取り除きます。
get_url = target_url.replace('KEY1=','')その結果、検索窓に 扇風機 をいれたURLが下記となります
というわけで、やっとURLをゲットです。
https://www.edion.com/item_list.html?keyword=%E6%89%87%E9%A2%A8%E6%A9%9Fwebdriverでブラウザーを起動、html情報を取得
requests BeautifulSoup を使用したスクレイピンの場合は
requests.get(target_url)
で全体情報を取得し、BeautifulSoupで欲しい詳細を取得していました。
今回使用するweb driverの場合は実際にブラウザーを起動して
そこから情報を取得していきます。
まずはブラウザーの起動、インスタンスを作成します。
こちらを起動すると空白のchromeが起動します。
#その都度最適なChromdriverをインストールして実行
browser = webdriver.Chrome(ChromeDriverManager().install())そして先ほど作成したキーワードをもとにURLを作成するプログラム
でアドレスを作成します。
#入力した検索文字を変改してURLを作成
key_word='扇風機'
post_data = {'KEY1':key_word}
urlencode_post_data = urllib.parse.urlencode(post_data, encoding='utf-8')
url = 'https://www.edion.com/item_list.html?keyword={}'
target_url = url.format(urlencode_post_data)
get_url = target_url.replace('KEY1=','')作成したget_urlを先ほど作成したインスタンスの引数に渡します。
#ChromedriverにURLを渡してデータをゲット
browser.get(get_url)これで扇風機の検索結果のページがchrome上で開きます。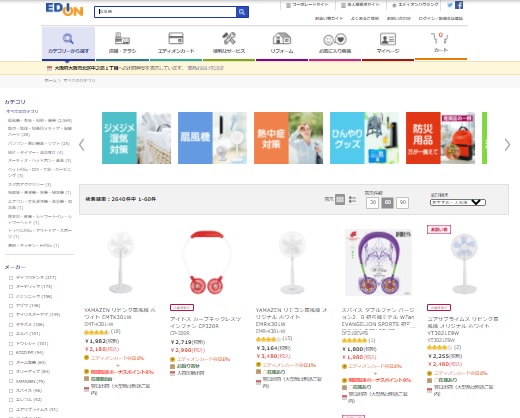
ここからは通常のスクレイピング同様、開いたブラウザーで
右クリック、検証でhtmlを開いて要素をしらべていきます。
検索結果から商品一覧のデータを取得
実際に取得していくとresultBoxの中に
<li></li>
<li></li>・・・
という型で検索結果が並んでいるのがわかりました。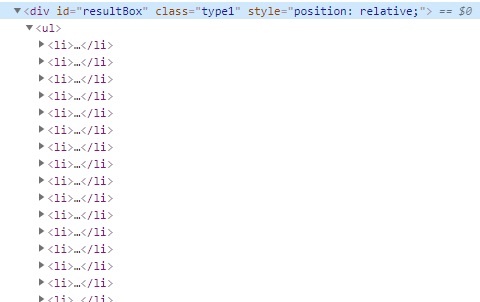
ここまでわかると一件のデータから各要素を取得して
for文でまわすと検索結果の情報全てが取得できるはずです。
requests BeautifulSoup を使用したスクレイピンの場合は
find find_all などで情報を取得していましたが、
今回は少しことなます。
取得したい情報毎に命令文が細分化されている感じです。
find_element一覧
#単体取得
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
#複数リスト取得
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selectorとりあえず要素の塊を取得します。
#ページデータから商品検索結果の全体を選択
ResultBox = browser.find_element_by_id('resultBox')
#liタグをリスト形式で取得
shouhins = ResultBox.find_elements_by_tag_name('li')これで商品群を取得することに成功したので
shouhins[0] で一つの商品から要素を取り出していきます。
ブラウザーの検証ツールで取得したのがこちらです。
#商品名
shouhin_mei = shouhins[0].find_element_by_class_name('item').text
#商品価格
shouhin_kakaku = shouhins[0].find_element_by_class_name('price1').text
#商品url
IBoxes = shouhins[0].find_element_by_class_name('imageBox')
shouhin_url = IBoxes.find_element_by_tag_name('a').get_attribute('href')ここまでくるとあとはfor文でまわします。
一件毎のデータを辞書型で格納して、
その辞書型で取得したデータをリストに格納します。
shouhin_list = []
for shouhin in shouhins:
shouhin_mei = shouhin.find_element_by_class_name('item').text
shouhin_kakaku = shouhin.find_element_by_class_name('price1').text
IBoxes = shouhin.find_element_by_class_name('imageBox')
shouhin_url = IBoxes.find_element_by_tag_name('a').get_attribute('href')
shouhin_info={
'namae': shouhin_mei,
'kakaku' : shouhin_kakaku,
'adress' : shouhin_url,
}
shouhin_list.append(shouhin_info)で、機嫌よく実行すると、エラーが
NoSuchElementException
一応作成したリストを確認してみると、
shouhin_list
[{'namae': 'YAMAZEN リビング扇風機 ホワイト EMTK301W',
'kakaku': '¥1,982(税別)',
'adress': 'https://www.edion.com/detail.html?_rt=IbghFA1ZbqvnvbcDE0qcPkhcbuTaAITKFREDh6zgc&p_cd=00060470430&_keyword=%E6%89%87%E9%A2%A8%E6%A9%9F'}]
どうやら一件だけデータは取得できたみたいです。
なぜエラーが出たのかこれからいろいろ調べてみたのですが、
結果からいいますと、商品群を取得したリストを
len()で件数を確認してみると
len(shouhins)
100100件???
実際に検索したページを確認してみると
検索結果は60件でした。
どうやら、各商品の中にさらに<li>タグを持っているものがあたらしく
その部分でエラーが発生していたみたいでした。
こんな感じであまりにも綺麗に並んでいたのですっかり騙されました(笑)
各要素毎にfor文をまわしてデータフレームで結合
ということで、今回は各要素毎にfor文をまわして
後で結合することにしました。
#liタグから商品リストを作成しようとしたが、
#商品の中にもliタグがあった為、固有情報を個別にfor文をまわして取得
items_names = ResultBox.find_elements_by_class_name('item')
items_prices = ResultBox.find_elements_by_class_name('price1')
ImageBoxes = ResultBox.find_elements_by_class_name('imageBox')
#商品名のリストを作成
prodact_names=[]
for item in items_names:
item_name = item.text
prodact_names.append(item_name)
#価格のリストを作成
prodact_prices=[]
for price in items_prices:
item_price = price.text
prodact_prices.append(item_price)
#URLのリストを作成
prodact_urls=[]
for ImageBox in ImageBoxes:
item_url = ImageBox.find_element_by_tag_name('a').get_attribute('href')
prodact_urls.append(item_url)
#リストをまとめてデータフレーム作成、同時にカラム名も指定
df = pd.DataFrame(list(zip(prodact_names , prodact_prices , prodact_urls)), columns = ['商品名','価格','URL'])
df.index = df.index + 1
df.to_csv(key_word + '.csv' ,encoding='utf_8_sig' )これでなんとか検索結果をcsv出力することに成功しました。
いろいろ紆余曲折あって結構楽しめました。
Python スクレイピング関連記事




コメント