
スクレイピングする題材
今日でPythonの学習を始めて82日目となりました。
普段は主に今西航平先生のyoutube動画で講義を受講しながら
勉強を進めてきました。
自分自身の備忘録も兼ねてブログを更新してきましたが、
一度自分でプログラムを組んでみようと思います。
ここからの内容についてはpythonのプログラムを
jupyter notebook
で記述していきます。
インストールなどまだな方は予めインストールが必要です。
"jupyter notebook" "インストール"などで
ググっていただくといいかと思います。
初めて自作するにあたって
どんな題材がいいかなぁ~と考えましたが、
今まで受講した講義の中で
webスクレイピング関係の講義が凄く面白かったので
今回はそれにしようと思います。
【スクレイピングに興味を持った以前の講義】
ランキングサイトの掲載情報を全て自動で取得する方法
実際にスクレイピングする題材もいろいろ悩みましたが
ランキングサイトの掲載情報を全て自動で取得する方法を学んだので
その技術でランキングデータを取得してみたいと思います。
そこで選んだのがこちら
↓ ↓ ↓ ↓ ↓ ↓
楽天市場 スマートフォン・タブレットランキング
の情報をwebスクレイピングで取得しようと思います。
スクレイピング可能かどうか調べる
スクレイピングするにあたってそのサイトがスクレイピング
可能かどうか事前に調べます。
といっても私自身そこまで詳しいわけではないので
ネットで調べた知識でサクッと調べます。
スクレイピンの技術は大変便利な反面、プログラムで連続して
処理をリクエストしますのでサーバーに負荷がかかってしまいます。
なので、スクレイピング、自動処理などを断っているサイトが多いようです。
そこで楽天市場の利用規約ページへ行き、事前に調べます。
楽天ショッピングサービスご利用規約 click
Windowsの方なら Ctrl + F 、
Macの方なら command + F
でページ内の文言を検索することができますので、
[ロボット、自動、スクレイピング、クローリング]
などの単語で検索結果が出てこなければ概ね大丈夫です。
とはいえ、相手方サーバーに負荷のかかりにくいプログラムを
作る必要はあります。
ライブラリのインストール
スクレイピングに必要なライブラリをimport します。
サーバーにリクエストを送ってhtmlデータを取得する
requests
取得したhtmlデータから div タグの class名 xxxx を取得
できるようにしてくれる
BeautifulSoup
最後に取得したデータをデータフレームに入れて
csv出力しますので、
pandas
この三つをimportします。
from bs4 import BeautifulSoup
import requests
import pandas as pdまずはランキングデータの塊を見つける
今回のターゲットである
楽天市場 スマートフォン・タブレットランキング
のurlをurlという変数に代入します。
その変数をrequests.get()の引数に渡し、htmlデータを取得。
取得したデータを変数resに代入。
さらにそのデータをBeautifulSoupの引数にいれて
soupインスタンスを作成。
url ='https://ranking.rakuten.co.jp/daily/564500/'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')と、ここまではエラーもなくスムーズに進みました。
これで取得したデータは見やすくなっているはずなので、
セルに
soup.text
と入力して実行してみます。
複雑、そして長い!(笑)
ある程度は予想していましたが、
実際のデータはやっぱり複雑です。
ただ、htmlの構造は根本的には同じはずなので
今西先生も講義のなかでおしゃっていました
おおきな塊をchromの検証ツールで探します。
chromで対象のホームページを開き、
ページ上で右クリック。
すると”検証”という項目が出てきますので、クリックすると
html と webページが二画面で表示されます。
検証ツールのポインターをクリックして
webページ上を動かしていくと対象個所の色が反転して、
そこを構成するhtmlが表示されます。
微妙なマウスの動きでランキングデータ部分全体を覆う
html部分を発見。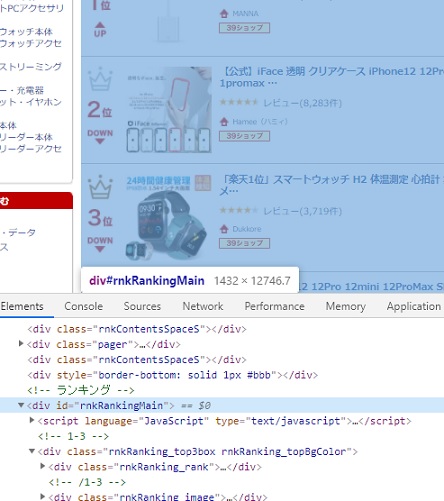
div タグの class が rnkRanking_upperbox というパーツを発見。
タグとclassがわかれば、soupインスタンスでfind_allというメソッド
を使って該当部分を探し出し、soups に代入します。
soups = soup.find_all('div', attrs={'class':'rnkRanking_upperbox'} )早速取得したsoupsをセルに入力して実行。

おぉぉぉぉ!
ランキングデータが取れてるっぽい!!
次はランキングデータの中から0番目のデータを取り出し、
その一つから必要なデータを取得していきます。
なんだか今西先生の講義が生かされてる感じがします!
ランキング全体から一件のランキングデータを取得
soupsはランキングデータが順位別にリスト形式で入っていますので、
soups[0]とセルに入力して実行すると
一位のデータが取得できます。
soups[0]
<div class="rnkRanking_upperbox">
<div class="rnkRanking_itemName"><a href="https://item.rakuten.co.jp/keitai/41-907/?l2-id=Ranking_PC_daily-564500-d_rnkRankingMain&s-id=Ranking_PC_daily-564500-d_rnkRankingMain_1">【公式】iFace 透明 クリアケース iPhone12 12Pro 12ProMax iPhone8 iPhoneSE 第2世代 se2 iPhone11 11pro 11promax …</a></div>
<div>
<div class="rnkRanking_starBox">
<div class="rnkRanking_starON"></div>
<div class="rnkRanking_starON"></div>
<div class="rnkRanking_starON"></div>
<div class="rnkRanking_starON"></div>
<div class="rnkRanking_starHALF"></div>
<div class="rnkRanking_starTgif"><img alt="" height="1" src="https://r.r10s.jp/com/img/home/t.gif" width="5"/></div>
<div><a href="https://review.rakuten.co.jp/item/1/191345_10801623/1.1/">レビュー(8,268件)</a></div>
</div>
</div>
<div class="rnkRanking_shop"><a href="https://www.rakuten.co.jp/keitai/">Hamee(ハミィ)</a></div>
<div id="rnkRanking_39shop1"></div>
</div>この商品データから
商品名などのデータを取得していきます。
Python 無料で独習 楽天市場ランキングのデータをスクレイピング 002
続き⇒
Python スクレイピング関連記事


コメント