
楽天市場ランキングのデータをスクレイピングその2
前回の記事、Python 無料で独習 楽天市場ランキングのデータをスクレイピング 001 はこちら
ランキング一位のデータから商品名を取得
商品名の入ったデータを探していると
<div class="rnkRanking_itemName"><a href="https://item.rakuten.co.jp/lakko/kbr-004/?l2-id=Ranking_PC_daily-564500-d_rnkRankingMain&s-id=Ranking_PC_daily-564500-d_rnkRankingMain_1">
Lightning SDカードカメラリーダー iPhone iPad 専用 iPhone12/11/11pro/X/XS/XR/8 plus/8/7/7plus/6/6s/6s plus/5s対…</a></div>div タグの中に rnkRanking_itemName というまさしく商品名
という部分を発見。
これをfindで抽出したものをRank_Nameという変数に代入。
このままだと余分なデータが含まれているので
.textでテキスト部分だけを抽出して商品名をゲット。
#0番目のデータを取得
Rankdata = soups[0]
#クラス名でデータを取得
Rank_Name = Rankdata.find('div', attrs={'class':'rnkRanking_itemName'} )
#デキストデータのみを抽出し、Rank_Nameに代入
Rank_Name = Rank_Name.text
Rank_Name
'Lightning SDカードカメラリーダー iPhone iPad 専用 iPhone12/11/11pro/X/XS/XR/8 plus/8/7/7plus/6/6s/6s plus/5s対…'同様にして商品urlとお店の名前も取得してみます。
Rank_url = Rankdata.find_all('a')[0].get('href')Rank_url = Rankdata.find_all('a')[0].get('href')
shop_name = Rankdata.find('div', attrs={'rnkRanking_shop'} ).text一件分のデータからfor文で全てのデータを取得
商品名、商品url、お店の名前を取得することができたので
それらを一度まとめてみます。
Rankdata = soups[0]
Rank_Name = Rankdata.find('div', attrs={'class':'rnkRanking_itemName'} )
Rank_Name = Rank_Name.text
Rank_url = Rankdata.find_all('a')[0].get('href')
shop_name = Rankdata.find('div', attrs={'rnkRanking_shop'} ).textこのデータをfor文の形に変えます。
for Rankdata in soups:
Rank_Name = Rankdata.find('div', attrs={'class':'rnkRanking_itemName'} )
Rank_Name = Rank_Name.text
Rank_url = Rankdata.find_all('a')[0].get('href')
shop_name = Rankdata.find('div', attrs={'rnkRanking_shop'} ).text取得したデータをリスト形式で格納
これでデータは取得できますが、蓄積しないといけません。
そこでまず空のリストデータを作ります。
そこへ辞書型で格納された一件ごとのデータを格納します。
その辞書型データを定義したリストにappendで追加していきます。
#空のリストを作成
data=[]
for Rankdata in soups:
Rank_Name = Rankdata.find('div', attrs={'class':'rnkRanking_itemName'} )
Rank_Name = Rank_Name.text
Rank_url = Rankdata.find_all('a')[0].get('href')
shop_name = Rankdata.find('div', attrs={'rnkRanking_shop'} ).text
#ランキングデータを辞書型で一件毎に格納
ranking_item={
'商品名':shop_name,
'商品url':Rank_url,
'お店の名前':shop_name
}
#リストに辞書型データを追加していきます。
data.append(ranking_item)取得したデータをpandasのDataFrameに格納、csv出力
ランキングデータの入ったリストデータ、dataを
pandasのデータフレームに変換します。
df = pd.DataFrame(data)このままcsv出力をすることも可能ですが、
このままですとindex番号が 0 始まりになります。
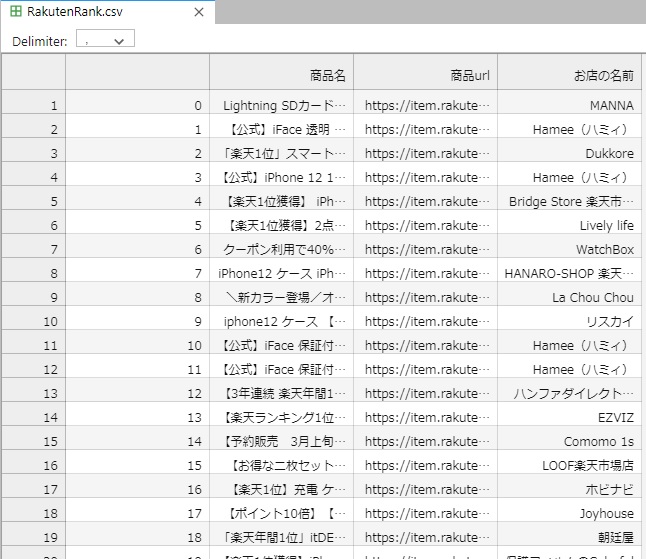
そこでcsvに出力する前にindexを全て +1 します。
df.index=df.index+1こまでくるとあと一息です。
csv出力しますが、文字化けを防ぐためにencodingします。
df.to_csv('RakutenRank_item.csv', encoding='utf_8_sig' ,)これで楽天ランキングを取得するプログラムは完成です。
一連の流れを下記にまとめます。
url の部分を変えるとそのランキングを取得することができます。
楽天ランキング取得pythonプログラム
from bs4 import BeautifulSoup
import requests
import pandas as pd
url ='https://ranking.rakuten.co.jp/daily/564500/'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
soups = soup.find_all('div', attrs={'class':'rnkRanking_upperbox'} )
data=[]
for Rankdata in soups:
Rank_Name = Rankdata.find('div', attrs={'class':'rnkRanking_itemName'} )
Rank_Name = Rank_Name.text
Rank_url = Rankdata.find_all('a')[0].get('href')
shop_name = Rankdata.find('div', attrs={'rnkRanking_shop'} ).text
ranking_item={
'商品名':shop_name,
'商品url':Rank_url,
'お店の名前':shop_name
}
data.append(ranking_item)
df = pd.DataFrame(data)
df.index=df.index+1
df.to_csv('RakutenRank_item.csv', encoding='utf_8_sig' ,)前回の記事、Python 無料で独習 楽天市場ランキングのデータをスクレイピング 001 はこちら
Python スクレイピング関連記事


コメント