
【番外編】スクレイピングせずにwebページ上の表データを取得する方法
タイトルが番外編となっていますが、
今回の講義では今まで使ってきた
BeautifulSoup や Seleniumを使用せずに
webページ上にある表データを取得する方法らしいです。
とても興味深いです。
今回の講義につかうのは
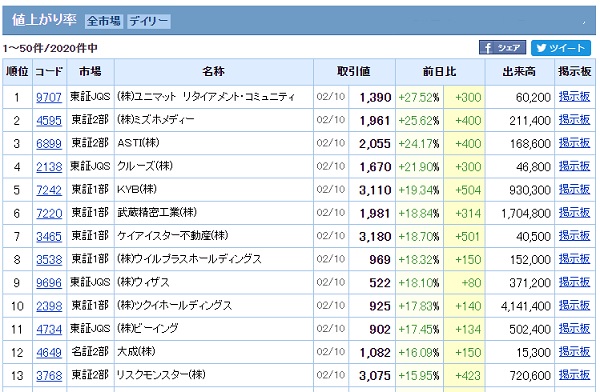
Yahoo ファイナンスの>株式>株式ランキング
です。
https://info.finance.yahoo.co.jp/ranking/
検証ツールで
<table>タグでつくられいることを確認します。
どうやら今回の方法は<table>タグのデータ取得に特化しているようです。
で、講義を見ているとどうやらpandasを使うみたいです。
しかもpd.read_html
pandasにそんな機能もあるんだ!!!
すごく楽しそうな機能なので早速コードを入力!
import pandas as pd
url = 'https://info.finance.yahoo.co.jp/ranking/'
dfs = pd.read_html(url)ImportError: lxml not found, please install itの対処
入力後、shift + enter を押すと、エラーが。。
ImportError: lxml not found, please install itなんだかよくわかりませんが、lxmlをインストールしろ
みたいなことが書いてあるので早速インストール。
!pip install lxmlインストールが完了したので再度shift + enter
ところがまた同じエラー
ImportError: lxml not found, please install it
しかたがないので、このエラー名で検索してみると
lxmlをインストールするだけじゃダメで、
bs4 と html5lib もインストールしなさいとあったので
bs4に関しては以前にインストール済だったので
html5libだけをインストールしました。
するとやっとデータの取得に成功しました!
import pandas as pd
url = 'https://info.finance.yahoo.co.jp/ranking/'
dfs = pd.read_html(url)
dfs
[ 順位 コード 市場 名称 取引値 取引値.1 前日比 \
0 1 9707 東証JQS (株)ユニマット リタイアメント・コミュニティ 02/10 1390 +27.52%
1 2 4595 東証2部 (株)ミズホメディー 02/10 1961 +25.62%
2 3 6899 東証2部 ASTI(株) 02/10 2055 +24.17%
3 4 2138 東証JQS クルーズ(株) 02/10 1670 +21.90%
4 5 7242 東証1部 KYB(株) 02/10 3110 +19.34%
5 6 7220 東証1部 武蔵精密工業(株) 02/10 1981 +18.84%
6 7 3465 東証1部 ケイアイスター不動産(株) 02/10 3180 +18.70%
7 8 3538 東証1部 (株)ウイルプラスホールディングス 02/10 969 +18.32%
8 9 9696 東証JQS (株)ウィザス 02/10 522 +18.10%
9 10 2398 東証1部 (株)ツクイホールディングス 02/10 925 +17.83%
10 11 4734 東証JQS (株)ビーイング 02/10 902 +17.45%
11 12 4649 名証2部 大成(株) 02/10 1082 +16.09%
12 13 3768 東証2部 リスクモンスター(株) 02/10 3075 +15.95%
13 14 6613 マザーズ (株)QDレーザ 02/10 1230 +14.95%
14 15 5110 東証1部 住友ゴム工業(株) 02/10 1174 +14.09%
15 16 7623 東証JQS (株)サンオータス 02/10 585 +14.04% テーブルデータの取得
こうしてみるとpandasのインポートだけでコードが書けて
いるのですが、実際には裏の方でbs4 や html5libなどの
モジュールが機能しているだなぁ~と思いました。
で、取得したデータは [ から始まっているのでリスト形式とわかるので
len(dfs) とすると 1 が返ってきます。
ページを確認するとテーブルは一個なのでそれを取得しているようです。
ではリスト形式なので0番目を取得してはじめの五行を表示します。
df = dfs[0]
df.head()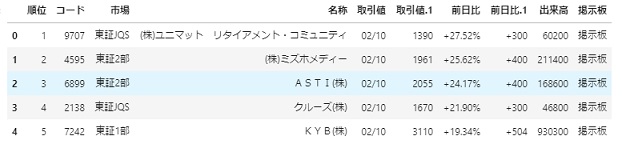
紆余曲折ありましたが、なんとかデータを取得できました。
ところが、これは文字列で取得しているので
ここから数値データなどを変換していくみたいです。
たとえば前日比のデータを取得すると文字列になっています。
df['前日比'][0]
'+27.52%'文字列を数値に変換するなどの後処理
まず取得したデータと実際のページを確認します。
実際のデータは取引値の所が日付と値になっているのに対して
取得データは取引値、取引値1
同様に前日比の部分も前日比、前日比1となっています。
まずはここから直していきます。
#現在のカラムを取得。コピペしてカラム名を変更したものをdf.columnsに代入します。
df.columns
Index(['順位', 'コード', '市場', '名称', '取引値', '取引値.1', '前日比', '前日比.1', '出来高', '掲示板'], dtype='object')
df.columns = ['順位', 'コード', '市場', '名称', '日付', '取引値.1', '前日比', '増加値', '出来高', '掲示板']
df.head()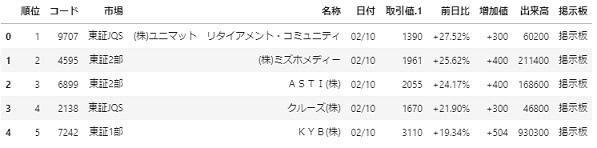
次は数値への変換です。
まずデータを確認すると最後の行が数値ではなく全て文字列が入っています。
これに気づかずにプログラミングするとエラーになります。
なのでhead() tail()などでこれから扱うデータの
特徴などを確認しておく必要があるとのことでした。
df.tail()
なのでこの最後の行を削除します。
df = df.drop(df.index[-1])
df数値への変換
データを見るだけなら、このままでもいいのですが、
後々集計したデータでなにかをする場合は
数字などが文字列のままだとあつかいにくかったりします。
その為にデータの中の文字列を数値に変えます。
変えたい列のカラム名をしていしてastypeとします。
df = df.astype({'順位':int})増加値などは+が前についていますので、
これを取り除く処理が必要です。
replaceで+をとりのぞき、その処理をfor文でまわすのですが、
今回今西先生は内包表記で説明されています。
df['増加値'] = [datum.replace('+','') for datum in df['増加値'].tolist()]これで下準備が整ったので、キーとバリューで指定して
一括でint型に変換します。
df = df.astype({'順位':int,'コード':int,'取引値':int,'出来高':int,})

コメント