
ログインなどのブラウザ操作を自動化しよう
プライベート、仕事上もとても興味があった
webスクレイピングの講義です。
Seleniumを用いたブラウザ操作
まずはseleniumのインストールです。
pipコマンドでjupyter notebook上でインストールします。
!pip install seleniumwebスクレインピングをするためのメソッドはいろいろ
あるらしいのですが、今回はブラウザの操作をするらしく
その場合はseleniumが適任らしいです。
で今回の講義ではもう一つ、chromedriverというのを
インストールする必要があるらしいです。
macを使われている方は
!brew install chromedriver
でインストールするらいしいです。
Windowsパソコンの場合は
Google で webdriver chrome で検索すると

というサイトが出てきます。
で、このchromedriverはいろいろバージョンがあって
今現在使用しているパソコンのchromのバージョンを調べて
それと同じか、近いバージョンのchromdriverをインストール
する必要があります。
バージョンを調べたら、それにあうバージョンをインストールします。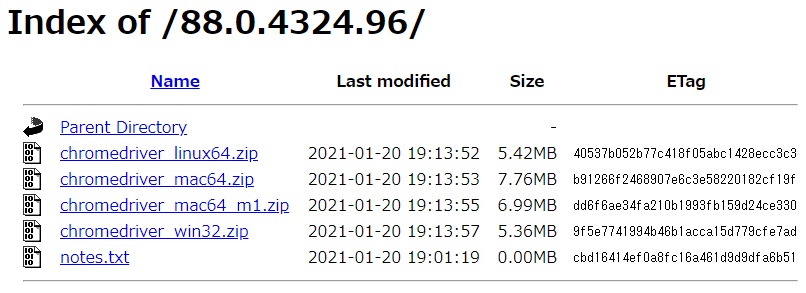
で、ダウンロートしたchromedriver.exeファイルは
作業ホルダーと同じ場所に置いておく必要があります。
別フォルダに入れて置きたい場合はパスを通す必要があります。
私は面倒なので、作業ホルダーに入れました。
これで前準備完了らしいです。
ではwebdriverのimport と ブラウザ操作の完了を待つために
3秒操作を止めたりする必要があるので
timeというメソッドをimport します。
from selenium import webdriver
from time import sleepここからコードを書いていきます。
chromeを起動します。
macの方は
browser = webdriver.Chrome()の1行でブラウザが立ち上がります。
windowsの場合はexeファイル名を引数にいれます。
browser = webdriver.Chrome('chromedriver.exe')初めて実行した時は「アクセスしてもいいですか」、みたいな
若干エラーみたいな表記がでましたが、許可するとそれ以降は
普通にブラウザーが立ち上がります。
開いたブラウザーは
browser.quit()
で閉じることができます。
で実際にwebページにアクセスするには
ブラウザを起動してget()で引数にurlをあたえます。
今回はテストでgoogleにアクセスしてみます。
browser = webdriver.Chrome('chromedriver.exe')
browser.get('https://www.google.com/')こうすると、ブラウザーを自動で起動し、
Googleのサイトにアクセスします。
なんか感動です!!(笑)
今回の講義は今西先生が講義用に立ち上げた
サイトを使ってスクレイピングを学びます。
そのURLがこちら
https://scraping-for-beginner.herokuapp.com/login_page
開いてみると、なにやらログインするページに飛びます。
こうして講義を見ていくと、
この今西航平先生はとても親切でわかりやすい講義を作られてるなぁ
と改めて関心します。
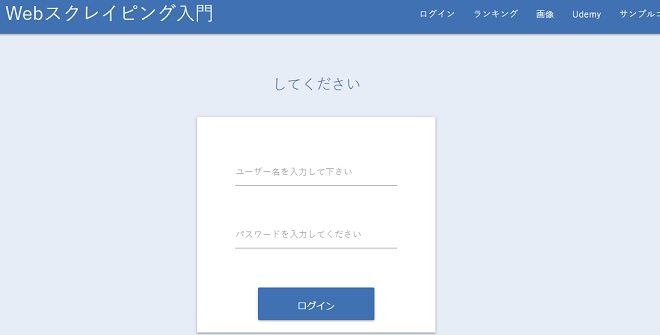
で、この講義ではこのサイトにアクセスして
ログインするところまでやるそうです。
先ほどGoogleにアクセスしたコードを少しいじって実行します。
直接URLを入れるのではなく、urlという変数にアドレスを
いれて、getに引数として渡します。
url = 'https://scraping-for-beginner.herokuapp.com/login_page'
browser.get(url)無事にホームページにアクセスすることができました。
ここからログインしていきます。
このサイトのアイパスは今西先生の名前になってます。
ユーザーネーム:imanishi
パスワード:kouhei
実際に自動処理をするにあたって大事なのが2点
・場所の特定
・アクション
まずは場所の特定です。
chrome検証ツールで場所の特定
それに必要なのがchromeの検証ツールです。
先ほどのホームページ上で右クリックする検証という項目があります。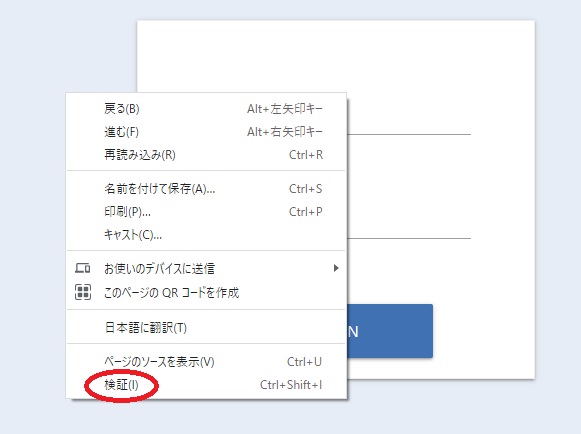
ここをクリックするとホームページとhtmlコードが
分割して表示されます。
そして検証ツールの矢印ボタンをおしてから
場所を特定した部分をクリックすると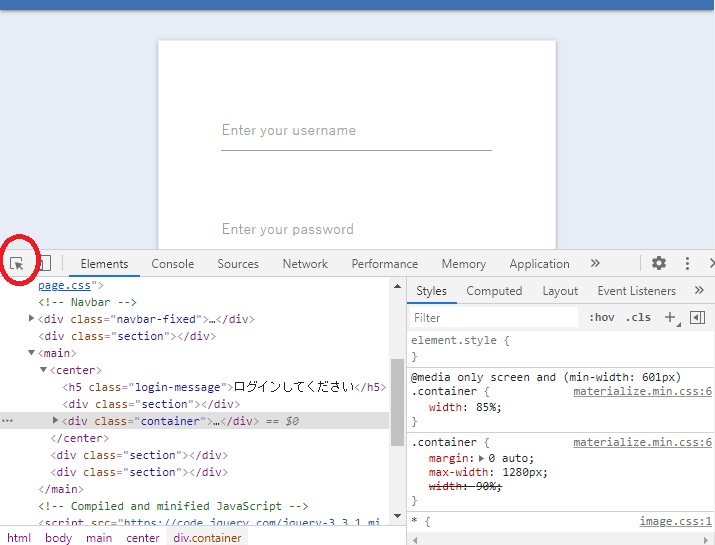
該当のhtmlをピンポイントで教えてくれます。
ものすごく便利です!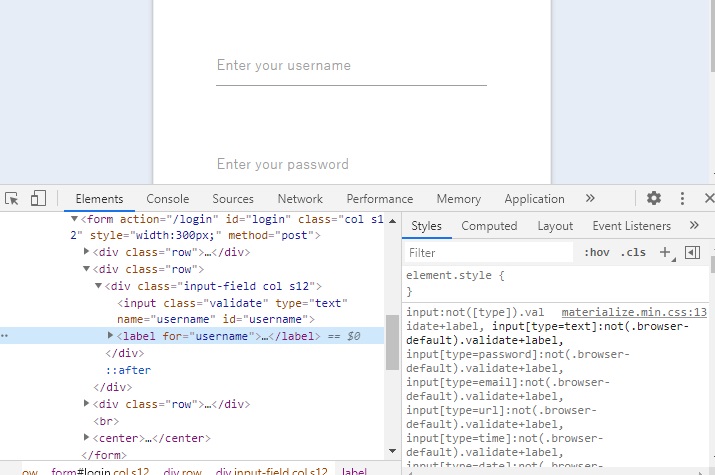
で実際に見てみるとユーザーネームをいれる場所は
id=username
となっています。
そのid名のものを探すメソッドが
browser.find_element_by_id('username')
となります。
これを変数にいれます。
elem_username = browser.find_element_by_id('username')これで場所の取得が完了です。
次はアクションです。
つぎはユーザーネームを入力するわけですが、
そのメソッドがsend_keys()です。
elem_usernameに先ほど定義したユーザーネーム:imanishiを入れます。
elem_username.send_keys('imanishi')同様にパスワードも入力します。
先ほどの検証ツールをつかうと
id がpassward となっていますので、
#場所の指定
elem_password= browser.find_element_by_id('password')
#実行する操作
elem_password.send_keys('kohei')とするとパスワードが入力されます。
最後はLoginBottnです。
これも検証ツールで場所を特定します。
id が login-btn となっています。
クリックするには名前もそのまま click()というメソッドを使います。
elem_login_btn = browser.find_element_by_id('login-btn')
elem_login_btn.click()これでブラウザーを開いて
ユーザーネーム、パスワードを入力し、
ログインボタンをクリックして完了です。
ながれをまとめると下記となります。
自動でブラウザーが開き、入力されていく様をみていると
正直ワクワクしました。
今西先生、今日もとても楽しい講義を有難うございました。
from selenium import webdriver
from time import sleep
browser = webdriver.Chrome('chromedriver.exe')
url = 'https://scraping-for-beginner.herokuapp.com/login_page'
browser.get(url)
sleep(4)
elem_username = browser.find_element_by_id('username')
elem_username.send_keys('imanishi')
elem_password= browser.find_element_by_id('password')
elem_password.send_keys('kohei')
elem_login_btn = browser.find_element_by_id('login-btn')
elem_login_btn.click()
今西航平先生に学ぶPython Webスクレイピング入門
vol 01 chromedriverをインストール ブラウサを操作するseleniumインストール
vol 02 find_elementで情報を取得 Pandasを使いdfに情報を入れcsvで出力
vol 03 requests.get()でページ情報を取得 BeautifulSoupで構造を解析
vol 04 ランキングサイトから情報を取得
vol 05 スクレイピングを利用した画像抽出方法
vol 06 pandas を利用したスクレイピング方法 テーブルデータの取得


コメント